Investment Risk Tolerance Assessment Tool
A lightweight, web-based risk assessment that turns a structured questionnaire into two outputs:
- a risk tolerance classification (e.g., Conservative → Aggressive)
- a simple starting allocation (equity vs. income)
This project is intentionally built to feel like a "friendly first pass" rather than an institutional-grade suitability engine: understandable, fast to complete, and designed to evolve as more anonymized responses are collected.
Screenshots
 Clean, minimal landing page with clear value proposition
Clean, minimal landing page with clear value proposition
 Interactive visualization to help users understand market volatility
Interactive visualization to help users understand market volatility
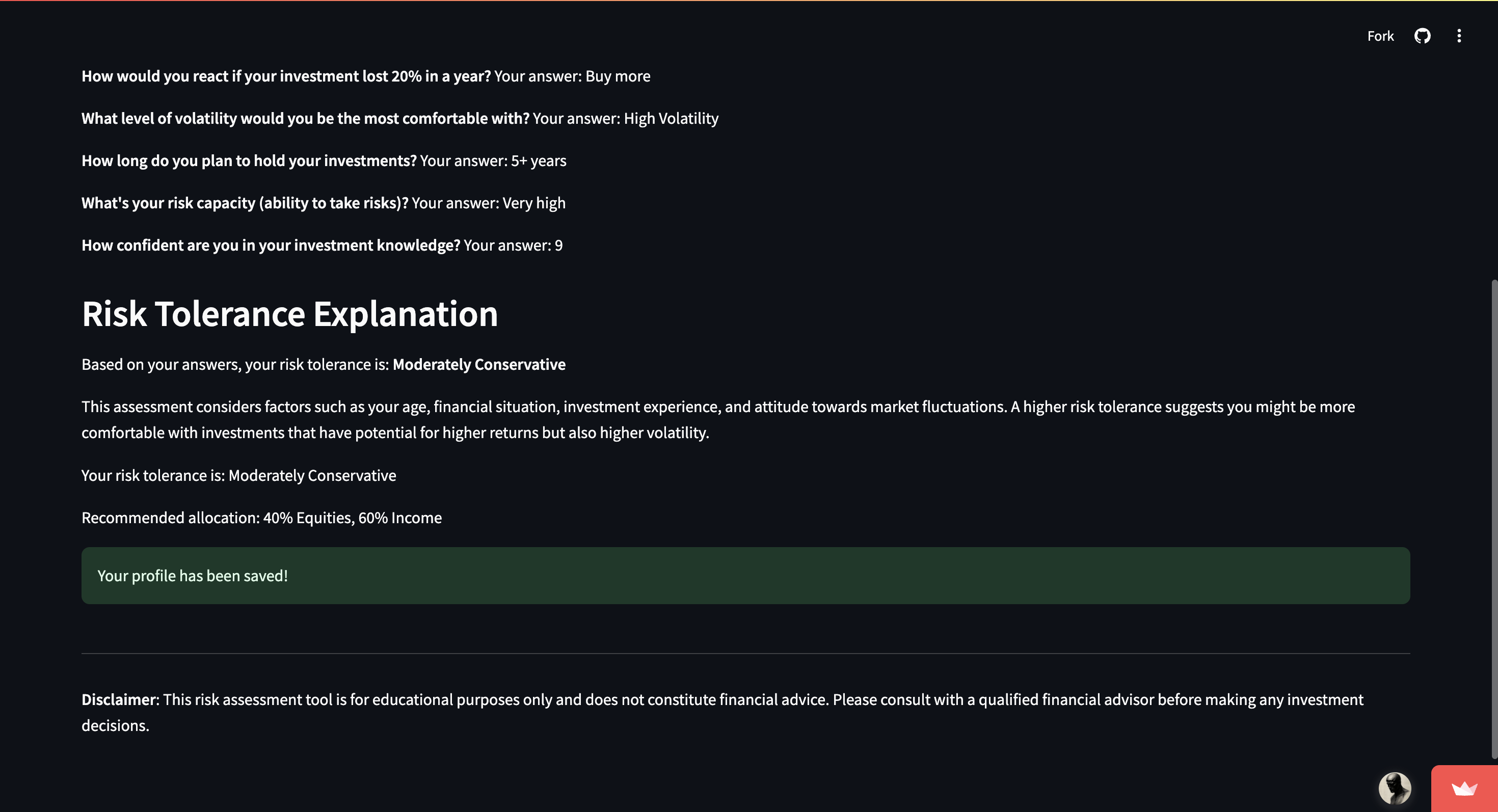 Clear risk classification with suggested allocation breakdown
Clear risk classification with suggested allocation breakdown
Why I built it
When I worked in financial services as a Financial Advisor, the “risk questionnaire” was always there—but it often felt like a black box: you answer questions, it spits out a label, and the reasoning is rarely obvious.
I wanted to explore a different approach:
- treat the questionnaire like a product (flow, clarity, user confidence)
- treat the scoring like a system (transparent baseline + data-driven improvement over time)
- treat storage like a responsibility (persist insights, minimize personal data)
- instead of just giving a specific result; "you inputted x, therefore buy mutual fund y" - the tool is intended to give a more granular understanding of what your risk levels are, and then the investor would keep that back of mind when doing research on what to invest in.
The result is a tool that can be used as a learning artifact, a starting point for investors, or a template for future automation work.
This is an educational tool—not financial advice. Use it to reflect, not to outsource judgment.
What it does
From the user’s perspective, the tool:
- guides you through a structured set of questions (financial context, experience, preferences)
- visualizes certain concepts (e.g., volatility comfort)
- returns a risk label and a basic allocation suggestion
- optionally stores anonymized responses for later analysis/model improvement
What I cared about (product constraints)
- Low friction: no account creation, no heavy onboarding
- Legibility: questions that feel human, not "compliance-form robot"
- Reversibility: back / restart controls and visible progress tracking
- Explainability by design: even before ML, the baseline model should be coherent
Architecture at a glance
Progressive Intelligence Flow
Rule-based foundation → ML enhancement → Transparent output
Questionnaire
Structured questions on financial context and preferences
Rule-Based Scoring
Deterministic baseline calculation
ML Enhancement
Data-driven refinement (when samples exist)
Risk Label
Conservative → Aggressive classification
Allocation
Suggested equity/income split
Anonymized Storage
Persist insights for model improvement
Hybrid approach: deterministic rules provide stability, ML adds refinement as data grows
Conceptually, the flow is:
- Collect inputs through a structured questionnaire
- Compute a risk score (rule-based baseline)
- Optionally predict score (ML model once enough data exists)
- Map score → label + allocation
- Persist anonymized record for future improvement
The core idea: “progressive intelligence”
A design choice I like here: the system doesn’t pretend ML is magic on day one.
Instead it uses:
- Rule-based scoring immediately (deterministic, explainable, stable)
- Machine learning only once there's enough data to justify it (avoids confident nonsense)
This keeps early predictions grounded while still giving the project a path to evolve into something more adaptive.
Why hybrid is better than “ML-first” (in a hobby project)
- ML needs data. Early on, you don’t have it.
- Rule-based logic is auditable and easier to calibrate.
- In finance-adjacent projects, “explainable” beats “clever” most of the time.
Privacy and data design
To improve the model over time, you need persistence—but you don’t need identity.
So the system stores anonymized response profiles (plus optional feedback), and keeps the storage footprint intentionally small and portable (SQLite + CSV for model training).
What I like about this approach:
- it enables longitudinal iteration
- it reduces the temptation to store sensitive user details
- it keeps the project deployable without heavyweight infra
What I learned building it
A few “earned lessons” from shipping a questionnaire-style product:
-
Most complexity is UX, not math.
The hardest part is keeping people engaged through the last question. -
People need visual anchors.
Even simple volatility visuals can dramatically improve comprehension. -
Deterministic systems are underrated.
A coherent scoring baseline can outperform a poorly-supported ML model. -
Feedback loops are a feature.
If the tool is meant to evolve, collecting feedback and responses matters as much as the model choice.
What I’d improve next
If I revisit this, I’d prioritize:
-
Richer result explanation
Not “because the model said so,” but a short rationale: which inputs mattered most. Maybe tucking in some form of NLP here and have a model (maybe VADER) generate a unique message based on the user's inputs. -
More allocation realism
Add cash, time horizon nuance, and “goal buckets” (retirement vs. near-term). Maybe use a financial data API to get related assets that fit the user's profile as suggestions on what they should be looking for based on results (ETFs, Mutual Funds, GICs, etc.). Not advice, just a quick: "hey, look at related assets that match your preferences" piece. -
Model evaluation + calibration
Make the ML handoff explicit: show when it switches from rules → model. -
Exportable results
A simple PDF/summary download for users.