Why I built this
A lot of “AI in finance” projects stop at a prediction: a probability, a label, a score. In real financial systems, that’s rarely the hard part.
The hard part is everything around the prediction:
- Can you explain why the system leaned approve vs. deny?
- Can you audit decisions and surface edge cases?
- Can the policy adapt without turning into a black box?
- Can you reason about tradeoffs (risk, fairness, customer experience) beyond raw accuracy?
This project was built to explore that boundary: not just a model, but an agent-like decisioning loop with a structured explanation layer and an adaptive policy mechanism.
This is a research prototype for learning and exploration—not production lending software.
What it does (high level)
Given a loan application feature vector, the prototype produces:
- a baseline risk estimate from a supervised model
- a decision (approve/deny or review bands, depending on configuration)
- a structured decision log that makes the outcome inspectable
- an optional reinforcement learning loop that attempts to update the policy from outcomes
Architecture at a glance
The system consists of three main components that work together in sequence:
- Baseline Model Layer → Random Forest classifier trained on historical credit data
- Decision Log Generator → Transforms model outputs into structured, human-readable reasoning traces
- Reinforcement Learning Loop → Optional policy refinement layer that learns from decision outcomes
The flow is straightforward:
- Input: loan application features (income, DTI ratio, credit score, employment history, etc.)
- Process: baseline risk estimate → structured decision log → optional policy adjustment
- Output: approve/deny recommendation + transparent reasoning trace
Note: A visual architecture diagram showing the model → decision log → RL loop is planned for a future iteration.
Core design idea: decision logs, not “mystical AI”
One easy trap in explainable finance tooling is confusing verbosity with explainability. Long narrative explanations can be persuasive while still being hard to audit.
Instead, I approached explainability as a decision log: concise, structured, and tied to the same features the model uses. The goal is to create output that is:
- easy to review
- easy to compare across cases
- easier to debug than pure narrative text
The system in three modes
1) Baseline supervised learning (risk estimation)
This is the foundation: a conventional classifier learns patterns from historical outcomes and estimates a risk probability.
What it answers: “Based on historical data, what is the likely outcome?”
2) Explanation layer (structured reasoning trace)
This layer does not try to mimic a human essay. It outputs a structured trace suitable for review.
A typical format looks like:
Decision: Further Review
Key factors:
- Debt-to-income ratio above threshold band
- Credit score in borderline range
- Loan amount high relative to income
Notes:
- Consider additional verification or compensating factors
The point is to make the decision process inspectable and repeatable, even as models evolve.
3) Reinforcement learning loop (policy refinement)
The RL component is intentionally simple: it explores whether an "approve/deny" policy can be improved using reward signals from outcomes.
What it answers: "Can we refine the policy over time without retraining the base model every time?"
This is also where real-world complexity shows up quickly:
- reward shaping matters
- delayed outcomes matter
- constraints matter (risk appetite, fairness boundaries, operational capacity)
That's exactly why it's interesting to prototype.
Results and what I actually care about
If you evaluate this purely as a classifier, you'll focus on accuracy. But the project's intent is different:
- produce decision + rationale in a consistent, reviewable structure
- create a foundation for thinking about learning loops in regulated decisioning
- force explicit discussion of tradeoffs (speed vs. safety, approvals vs. defaults)
In other words: less "prediction demo," more "system behavior prototype."
Visuals
Model Performance Comparison
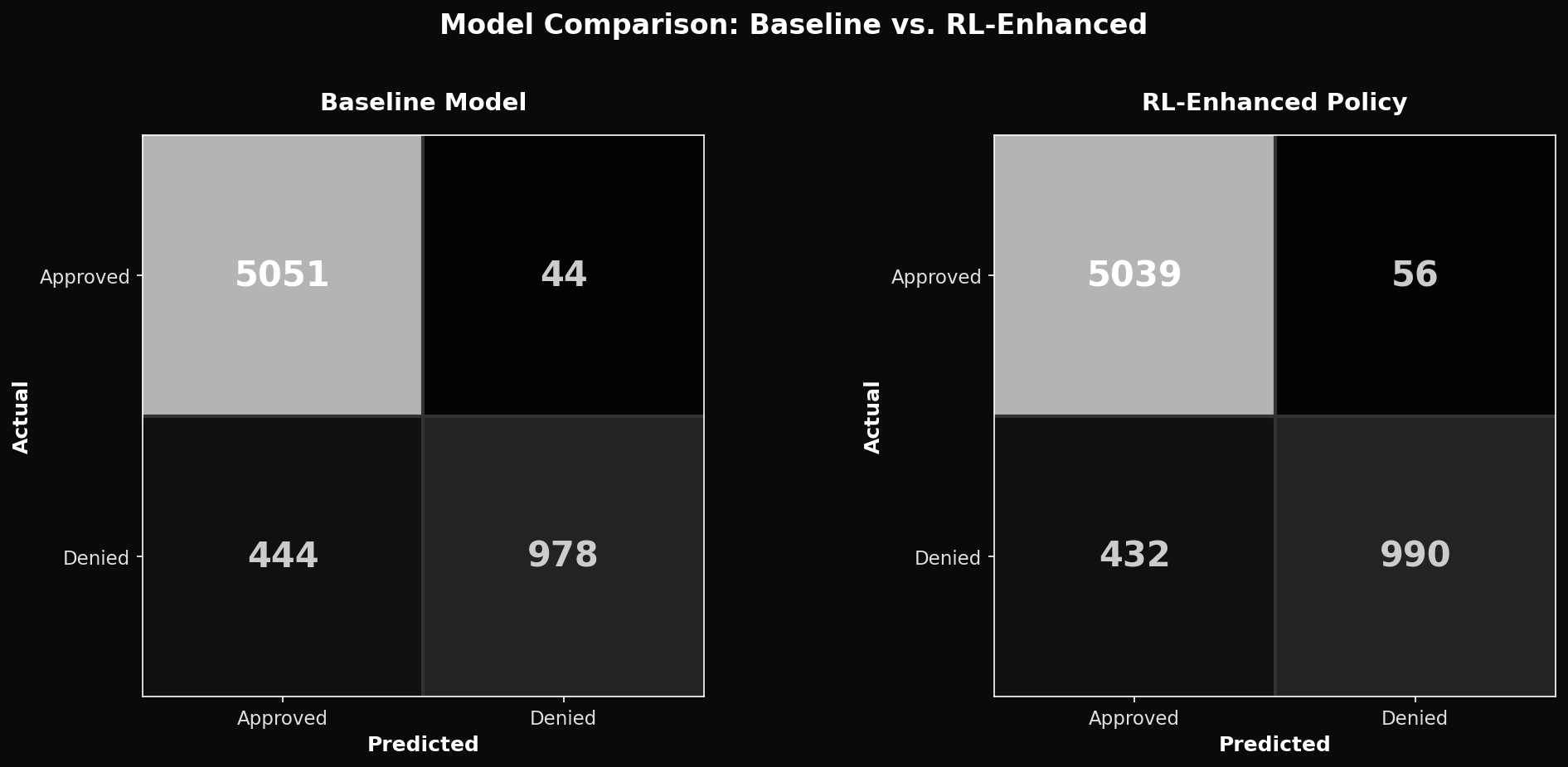
Baseline model vs. RL-enhanced policy: comparing false positive/negative rates
Feature Importance
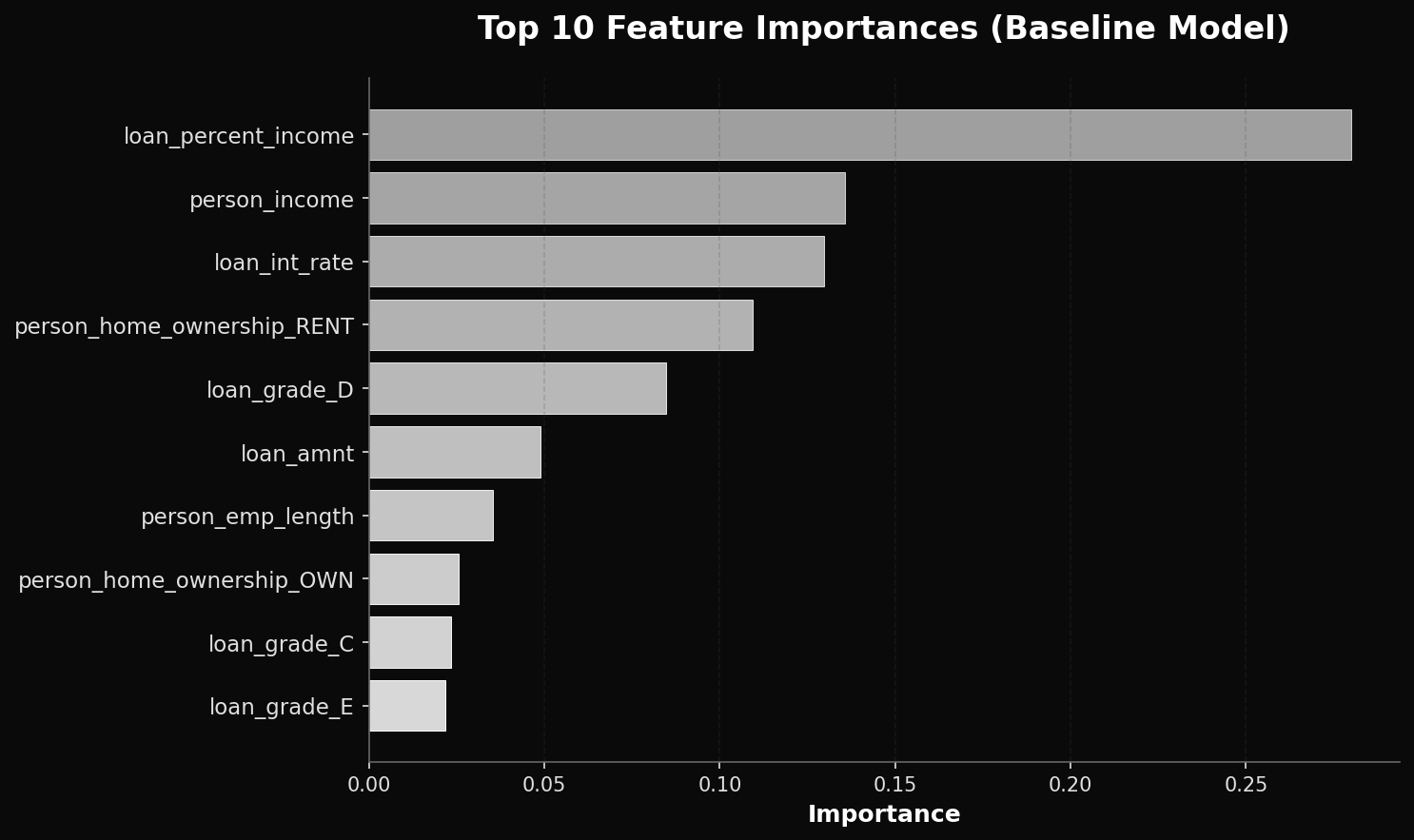
Top 10 features driving credit risk decisions in the baseline model
Decision Log Example
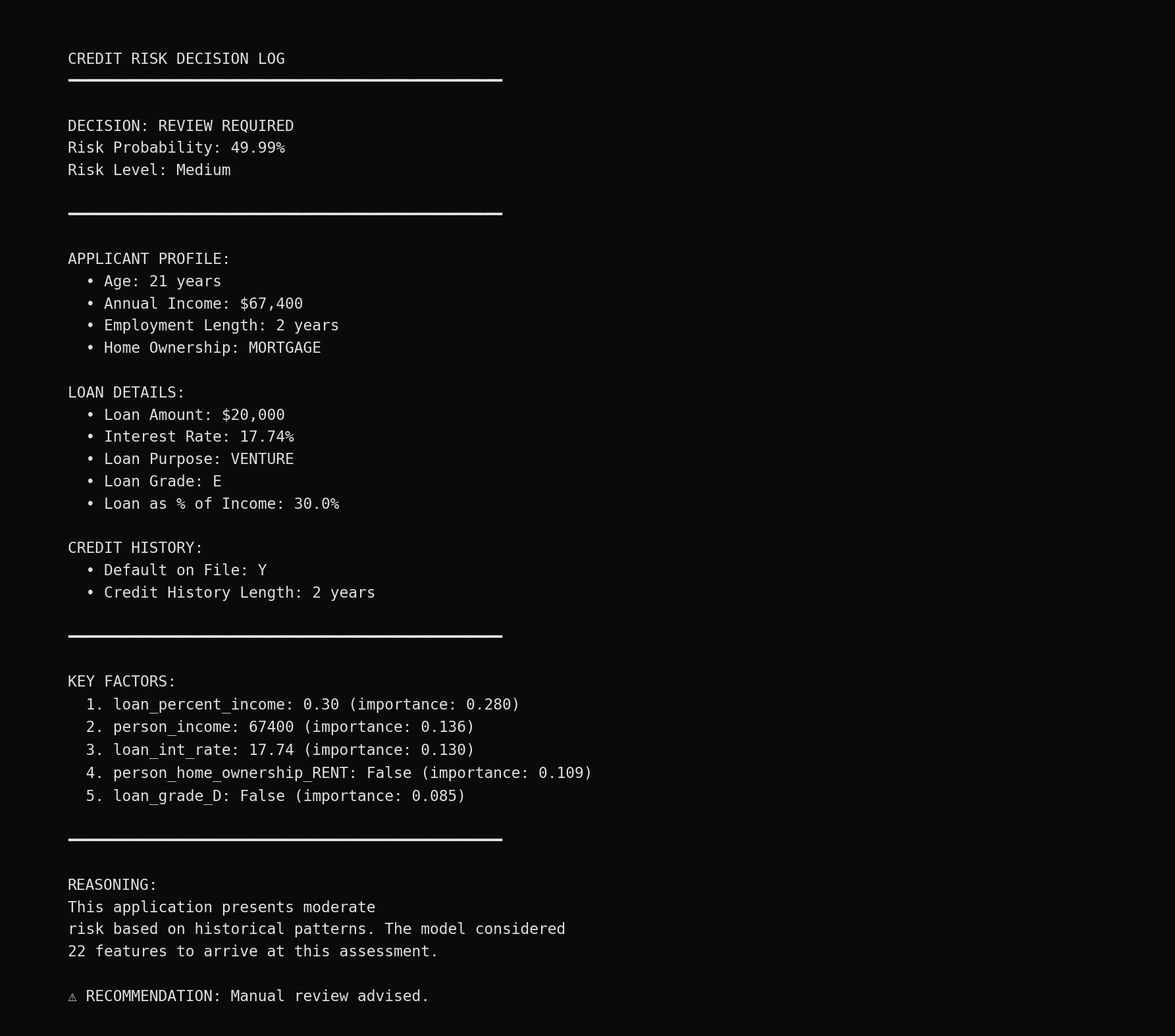
Structured decision log for a borderline case: transparent, auditable, and repeatable
What I'd improve next
If I were evolving this into a more serious iteration (still not production), the next steps would be:
- Handle imbalance explicitly (class weights / resampling / threshold tuning)
- Replace the simplistic RL framing with constrained optimization (loss + approval rate + fairness bands)
- Add governance scaffolding (versioning, audit sampling, decision review notes)
- Evaluate stability under drift (economic regime changes / shifting borrower profiles)
- Add a small UI for scenario testing and explanation review
Responsible use note
This project is for educational and research purposes and should not be used to make real lending decisions without a full compliance, fairness, and governance program.
Resources & Credits
Project Links
- Repository: GitHub - CoT-RL-Credit_Risk_Assessment
- In-Depth Article: Autonomous Agents and Chain of Thought Reasoning: A New Frontier (LinkedIn)
Dataset
This project uses the Credit Risk Dataset from Kaggle, which provides historical loan application data for training and evaluation.
- Source: Credit Risk Dataset on Kaggle
- Use: Training baseline supervised learning model and evaluating RL-enhanced policy improvements