Overview
The purpose of this project started as an internal automation challenge in a regulated financial environment. I wanted to demonstrate a practical “automation engineer / solutions architect” build: event-driven orchestration, structured LLM extraction, and end-to-end traceability—all wrapped into a workflow that can provide clients with immediate feedback on the provincial Articles of Incorporation they'd uploaded to complete an account application.
At a high level, the system watches for newly uploaded Articles of Incorporation, enriches that intake with submitted metadata (inputs from their online application), runs an automated verification pass (classification + extraction + comparison) to determine if Articles match the online application values (Directors/Owners/Officers, corporation name, checks if it's the complete Articles or a partial submission), and writes standardized results back into a tracking surface for downstream action the client must take if verification doesn't pass.
Note: The visuals and examples below are synthetically generated application values. The public write-up focuses on the architecture and engineering patterns, not any organization-specific details.
What it does
Inputs
- A newly uploaded Articles of Incorporation document (typically PDF)
- Basic metadata from a tracking surface (e.g., submitted application/entity details)
Outputs
- A structured verification result (JSON)
- An internal summary (operator-friendly)
- A customer-facing message (plain-language, action-oriented)
Architecture at a glance
Components
- n8n workflow for orchestration (Google Drive trigger → enrichment → service call → writeback)
- Verification service (API endpoint) to handle parsing + LLM calls + validation logic
- LLM extraction layer (Google Gemini via LangChain) with LangSmith tracing
- Google Drive + Google Sheets as the event source and ledger for mock customer application data
Data flow
n8n Cloud Workflow
Drive Folder Trigger
Watches BC_Articles_Incoming folder
Google Drive Download
Downloads the PDF file
Google Sheets Get Rows
Looks up application by ID
Merge Data Node
Combines file download and application details
Code Node
Merges data + converts PDF to base64
HTTP Request
POSTs to /analyze_articles endpoint
Google Sheets Append
Writes results back to sheet
FastAPI Backend (Local)
Decode base64 PDF
Converts base64 string back to PDF bytes
Extract text with pdfplumber
Parses PDF content into text
Classify document type
Gemini determines document type
Extract individuals/directors
Gemini extracts structured data
Compare directors against application
Validates extracted data vs submitted metadata
Generate summaries
Gemini creates internal + customer messages
Return structured JSON response
Sends verification results back to workflow
Workflow: step-by-step (operator view)
1) Event trigger
The trigger activates when a new file is uploaded to a folder in my Google Drive.
2) Download and metadata enrichment
The workflow downloads the file, then looks up relevant metadata from a Google Sheet (using a filter keyed to the new file or its identifier (i.e. APP-001)).
3) Merge + payload preparation
A merge step combines file + metadata, followed by a small JavaScript transform that:
- normalizes fields
- base64-encodes the file
- prepares a clean request body for the verification service
4) Service call
An HTTP POST sends the prepared payload to a verification endpoint that performs the analysis.
5) Writeback
The workflow appends a new row to a results sheet containing:
- verification status
- extracted parties (where applicable)
- a summary for internal operators
- a customer-facing instructional message
- (optional) confidence / notes
Verification service (analysis behavior)
The verification service is deliberately designed as a thin “decision layer”:
- it accepts a document + metadata
- produces a deterministic structured output
- and remains observable and debuggable through tracing
Typical analysis steps:
- Document type classification (is it the expected doc type?)
- Entity / director / officer / beneficial owner extraction
- Comparison against submitted metadata in online application synthetic samples
- Result formatting into an agreed schema
- Message generation (internal + customer-facing)
Observability (LangSmith)
A key design goal was making the pipeline explainable:
- each run is traceable end-to-end
- model calls can be inspected
- outputs can be evaluated and iterated without guessing
I used tracing to:
- identify weak extraction cases
- compare prompt variants
- quickly debug edge cases without drowning in logs
Guardrails and reliability
A few patterns that mattered in practice:
- Structured output contract: results are returned in a consistent JSON shape, so downstream steps don’t break when prompts change.
- Retry strategy & rate limits: API-driven workflows encounter transient failures; the pipeline is designed to fail gracefully and resume cleanly.
- Separation of concerns: n8n orchestrates; the service decides. This keeps the workflow maintainable and the verification logic testable.
Security and privacy notes
- Public materials use synthetic examples
- No secrets are committed; credentials live in environment variables / platform secret stores.
- In public demos, identifiers and names are either fake or anonymized.
What I’d improve next
If I were evolving this into a long-lived internal product, I’d focus on:
- A small review UI for exceptions and edge cases (human-in-the-loop)
- Better document parsing (layout-aware extraction for tricky PDFs)
- Evaluation harness with a curated test set and regression checks
- Role-based access + audit trails around who can view results and why
- Expand to other provincial articles I focused mainly on the province of British Columbia and their Articles/Certificates of Incorporation, would like to expand this to other provinces in the future.
Media
n8n Workflow Screenshot
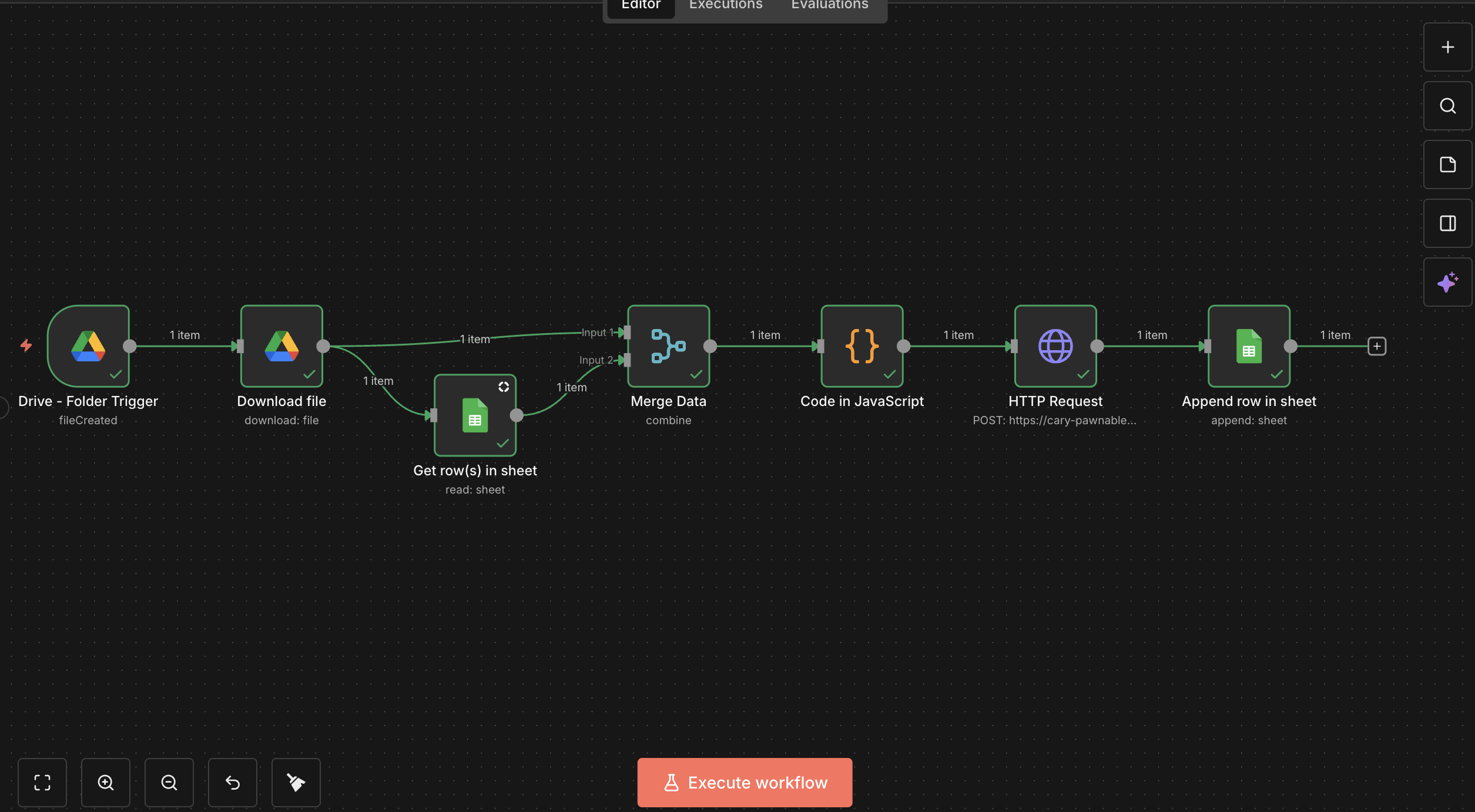
Complete n8n workflow showing the document verification pipeline
Example Output Response From Logs
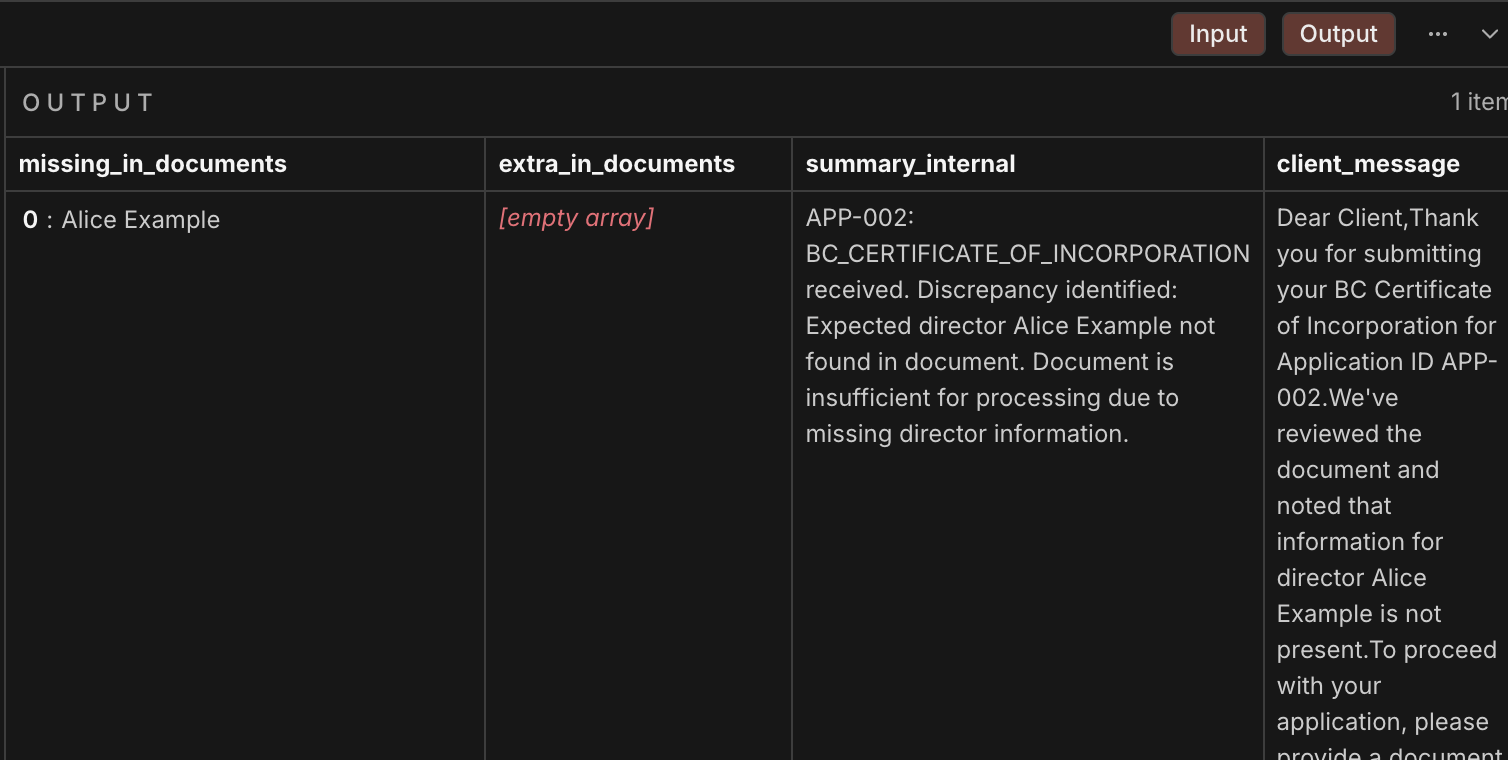
Detailed view of workflow nodes and configuration
A Complete Example Output (Synthetic)
{
"doc_type": "BC_CERTIFICATE_OF_INCORPORATION",
"sufficient_for_director_check": false,
"parsed_individuals": [
{
"name": "CAROL PREST",
"role": "Registrar of Companies"
}
],
"matches": [
{
"application_name": "Alice Example",
"status": "missing_in_documents",
"document_name": null
}
],
"missing_in_documents": ["Alice Example"],
"extra_in_documents": [],
"internal_summary": "APP-002: BC_CERTIFICATE_OF_INCORPORATION received. Discrepancy identified: Expected director Alice Example not found in document. Document is insufficient for processing due to missing director information.",
"customer_message": "Dear Client, thank you for submitting your BC Certificate of Incorporation for Application ID APP-002. We've reviewed the document and noted that information for director Alice Example is not present. To proceed with your application, please provide a document such as an Annual Report, Shareholder Agreement, or a Director's Resolution that clearly lists all current directors, including Alice Example. Please upload the additional document through your portal at your earliest convenience. Thank you for your cooperation."
}